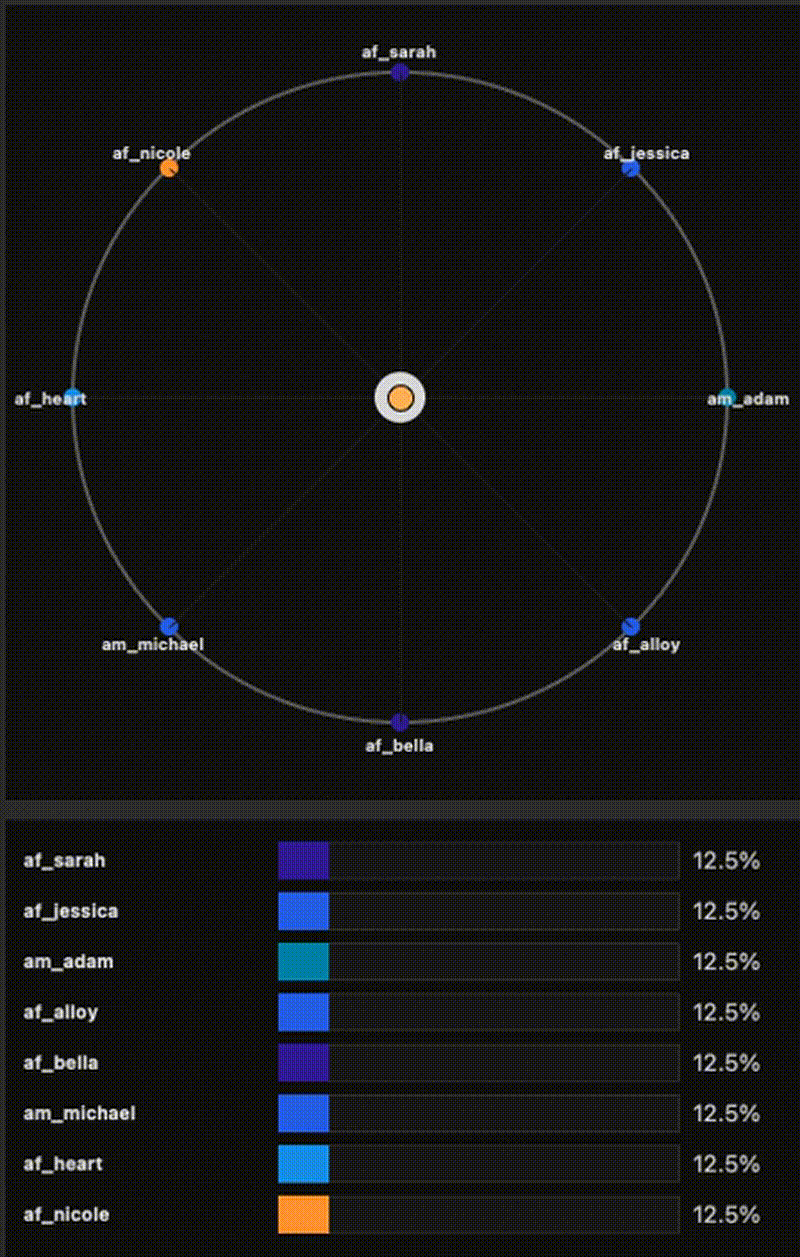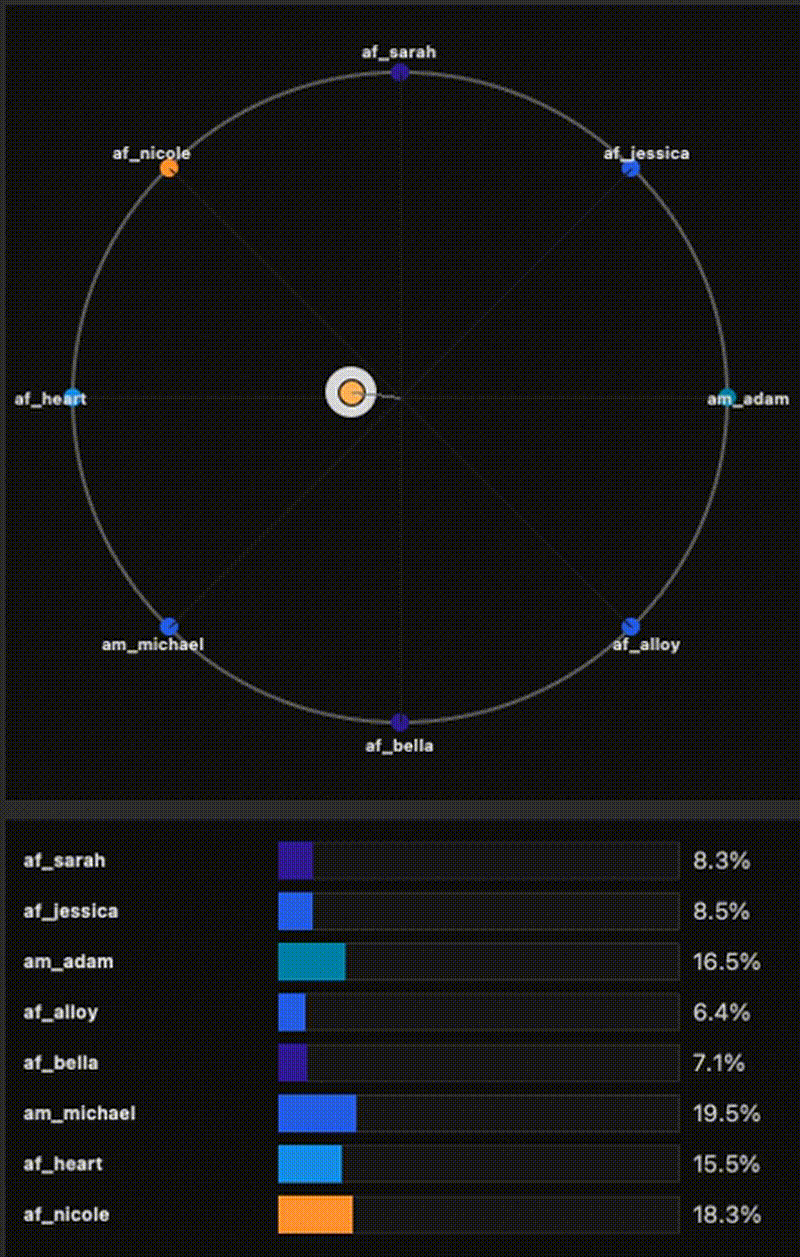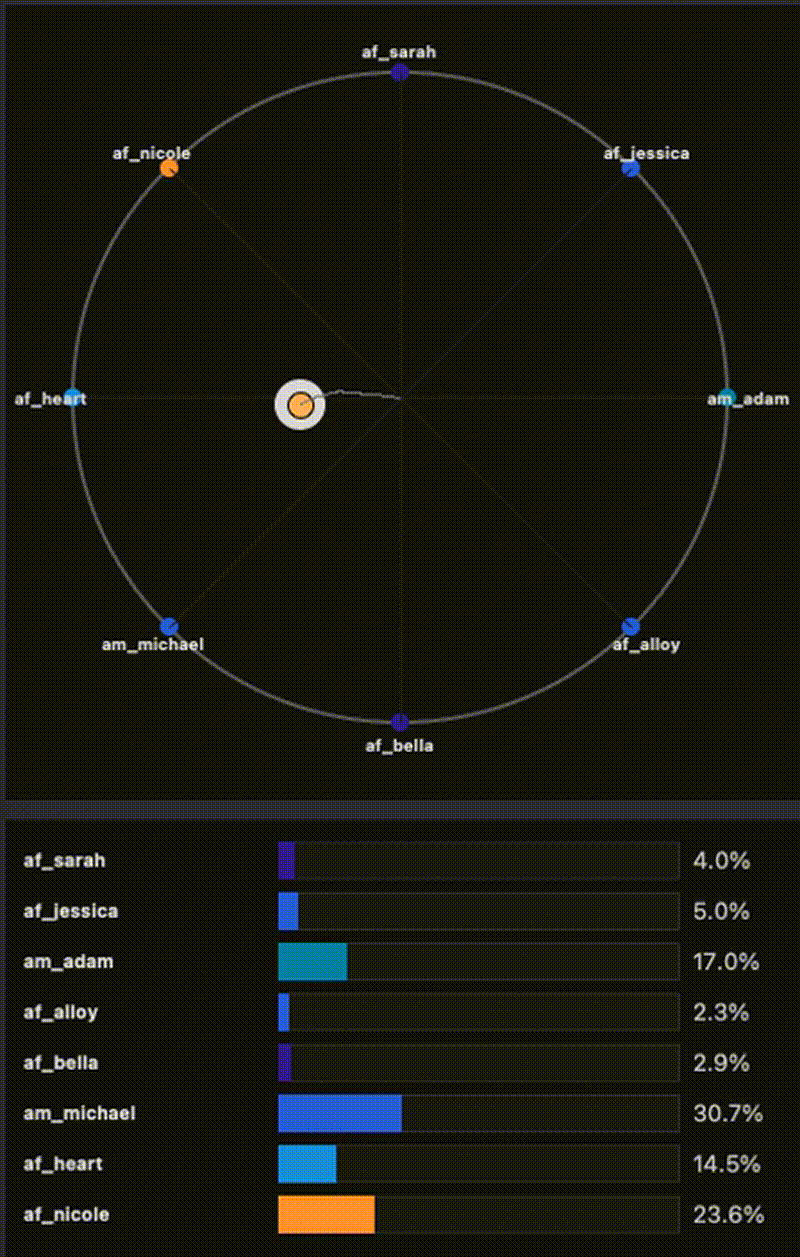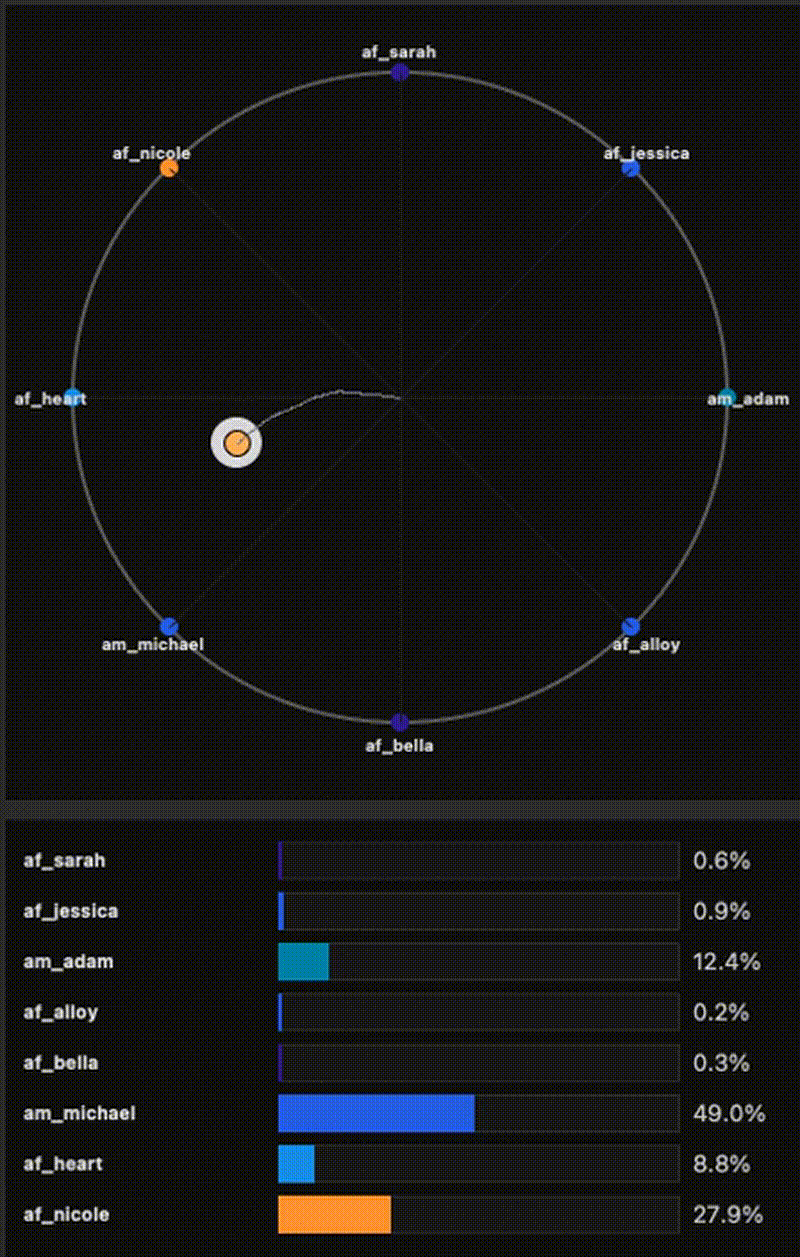
ES-EGGROLL — Post-training Text-to-Image with Evolution Strategies
An EGGROLL-style implementation of low-rank Evolution Strategies from “Evolution Strategies at the Hyperscale” (Sarkar et al., 2025), adapted for text-to-image alignment post-training. The base generator stays frozen, and we optimize only a LoRA adapter using black-box reward signals (e.g., PickScore as the objective), with CLIP / aesthetic / no-artifacts used as diagnostics. This enables fast iteration on alignment objectives at near inference throughput, without diffusion backprop. For extra details, results, and examples, visit the project website.
| Model | aesthetic ↑ | CLIP text ↑ | no artifacts ↑ | PickScore ↑ |
|---|---|---|---|---|
| SanaOneStep_Base | 0.5978 | 0.6592 | 0.3859 | 22.3220 |
| SanaOneStep_eggroll | 0.5975 | +0.00190.6611 | +0.00400.3899 | +0.179322.5013 |
| SanaTwoStep_Base | 0.5965 | 0.6614 | 0.3926 | 22.8059 |